
AP Syllabus focus:
‘Guidance on drawing inferences from sample data about the broader population. Discuss the importance of sample representativeness and random selection in ensuring that generalizations are valid and highlight the limitations of observational studies in making causal claims.’
Understanding how to extend findings from a sample to an entire population is essential for valid statistical reasoning and supports accurate, trustworthy conclusions in studies.
Making Inferences: From Samples to Population
The Purpose of Statistical Inference
Statistical inference allows researchers to use information from a sample to make reasoned statements about a population. Because studying every individual in a population is often impossible, inference provides a structured way to generalize findings beyond the sample actually observed. The quality of these generalizations depends heavily on how the sample was collected and whether randomness was used to reduce bias.
Population is introduced early in statistical studies, and it refers to the complete set of individuals or items of interest.
Population: The entire group of individuals or objects that a study aims to understand.
A sample is the smaller group selected from that population for measurement or observation.
Sample: A subset of the population chosen for study, ideally selected using a random method to support valid inference.
The relationship between sample and population lies at the heart of inference, creating a framework for estimating population characteristics using sample data.
Why Representativeness Matters
A sample must be representative, meaning it reflects the characteristics of the population reasonably well. When the sample resembles the population in composition and variation, conclusions drawn from the sample are more likely to be trustworthy.
A key component of representativeness is random selection, which gives each member of the population an equal chance of being chosen.
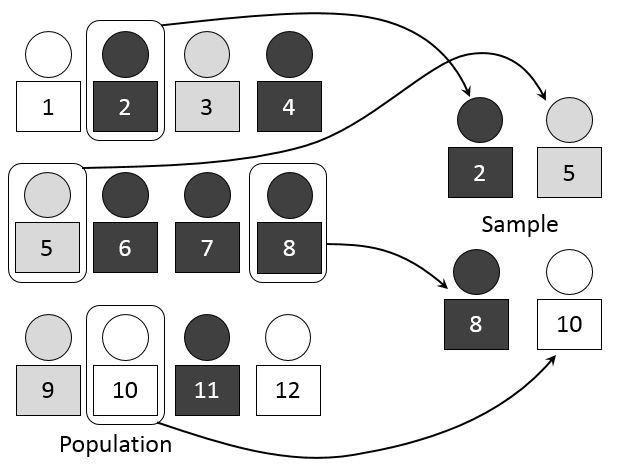
A visual representation of simple random sampling, showing how individuals are chosen randomly from a population to form a representative sample that supports valid inference. Source.
Random selection supports two major goals in inference:
It helps eliminate systematic error, allowing chance variation to govern which individuals enter the sample.
It ensures that observed patterns in the sample can plausibly be attributed to population-level patterns.
How Random Sampling Supports Valid Inference
Random sampling methods strengthen inference because they use chance to avoid predictable patterns in sample formation. When randomness is incorporated into data collection:
Results become less dependent on the choices or preferences of the researcher.
Observed sample statistics can be treated as unbiased estimates of the corresponding population parameters.
Probability theory can be applied to quantify uncertainty in sample-based estimates.
This link between randomness and inference is foundational in AP Statistics, supporting the use of sampling distributions, margin of error, and confidence intervals in later topics.
Sampling Variability and Uncertainty
Every sample differs from every other possible sample due to sampling variability, the natural variation that arises purely by chance. Because of this variability, no sample perfectly mirrors the population. Inference provides tools for measuring how far off a sample is likely to be from the true population value.
Researchers acknowledge and manage sampling variability by:
Using sufficiently large sample sizes.
Relying on random methods.
Interpreting results within a framework of probability rather than certainty.
These considerations allow students to understand why two samples from the same population may yield slightly different results and how inference accommodates this uncertainty.
Limits of Observational Data in Making Causal Claims
Inference from samples to populations concerns generalization, not causation. While random selection supports generalization, it does not permit claims about cause and effect. The syllabus emphasizes that observational studies, which involve no imposed treatments, cannot reliably establish causality. Observational studies may reveal associations, but uncontrolled variables can produce misleading relationships.
Important limitations of observational studies:
They cannot eliminate confounding variables.
They do not provide the controlled conditions needed to isolate explanatory factors.
They permit inference about populations only if random selection is used.
Because of these constraints, researchers rely on experimental design (covered elsewhere in the syllabus) to make causal claims.
Key Components of Drawing Valid Inferences
To ensure that inferences are accurate and statistically meaningful, researchers focus on several essential conditions:
1. Use of Random Selection
Ensures sample representativeness.
Allows the use of probability-based reasoning.
Prevents systematic bias in determining who participates.
2. Appropriate Sample Size
Larger samples reduce sampling variability.
Inference becomes more precise as sample size increases.
3. Clearly Defined Population and Sampling Frame
The target population must be specified before collecting data.
The sampling frame must closely match the population to avoid undercoverage.
4. Awareness of Study Design Limitations
Observational studies support generalization only.
Causal conclusions require well-designed experiments with random assignment, not random sampling.
The Role of Sampling Distributions in Inference
While formal work with sampling distributions occurs later in the course, the conceptual foundation begins here. A sampling distribution describes the values a sample statistic can take across all possible samples from the population.
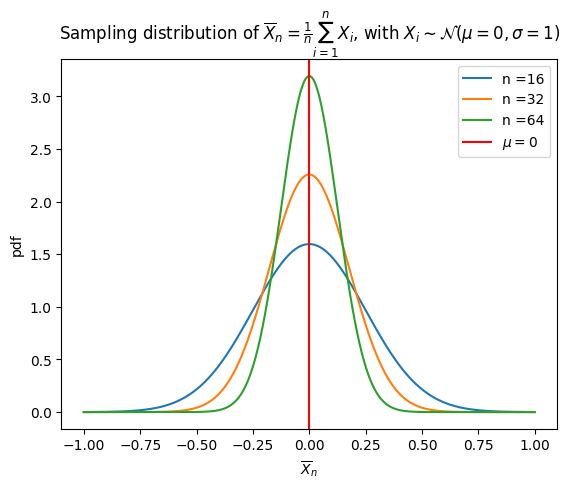
Sampling distributions of the sample mean for a normal population, showing how larger sample sizes narrow the distribution and reduce sampling variability, supporting more precise inference. Source.
Understanding this idea conceptually helps students appreciate why:
Randomness allows predictable long-run behavior.
Inference methods rely on probability models.
Individual sample results must be interpreted within a range of plausible outcomes.
These ideas build toward more advanced inferential techniques, reinforcing why high-quality data collection is essential from the outset.
FAQ
The sampling frame determines who is actually eligible to be selected for the sample, so any mismatch between the frame and the true population can distort results.
If groups are unintentionally excluded or underrepresented, the sample may no longer reflect the population, weakening the validity of generalisations.
Common issues include outdated lists, missing subgroups, or frames that capture only part of the population.
When the population is highly homogeneous, even small samples can provide reliable inferences because individuals do not differ greatly.
However, when the population is diverse, small samples may fail to capture important variation.
In such cases, reliable inference requires:
Larger sample sizes
Use of random selection
Careful definition of the target population
This occurs because of natural sampling variability: the idea that each random sample includes a slightly different mix of individuals.
Some samples may, by chance, contain more individuals with certain characteristics than others.
Inference accounts for this by evaluating:
How large the differences are
Whether the sample size is sufficient
Whether the patterns are likely to have arisen by chance
Researchers can compare characteristics of the sample with known information about the population, such as demographic distributions or historical data.
Other strategies include:
Reviewing the sampling method for issues such as clustering or accessibility constraints
Checking response rates to detect potential bias
Ensuring that the sampling frame covers the entire population
Random selection ensures that the sample reflects the population, which is essential for generalising findings.
However, causation requires controlling variables and ruling out alternative explanations.
Only experiments with random assignment of treatments can isolate cause-and-effect relationships; observational samples, even if randomly selected, cannot control confounding factors.
Practice Questions
A researcher selects a random sample of 120 students from a school to estimate the proportion of all students who walk to school. Explain why random selection is important when making an inference about the entire student population. (1–3 marks)
1 mark: States that random selection reduces or removes bias.
1 mark: States that random selection gives every student an equal chance of being included.
1 mark: States that this supports valid inference or allows the sample results to reflect the population.
Total: 1–3 marks depending on depth and clarity.
A town council wants to estimate the average amount of household waste produced per week by households in the town. They plan to randomly select 80 households from a list of all registered addresses.
(a) Explain why the council can generalise their findings to the wider town population.
(b) Identify one limitation of the study that might affect the accuracy of the inference.
(c) Suggest one modification to improve the reliability of the inference and justify your suggestion. (4–6 marks)
(a)
1 mark: States that the sample is randomly selected.
1 mark: Explains that random selection makes the sample representative of the population.
1 mark: States that representativeness allows generalisation from the sample to all households.
(b)
1 mark: Identifies a reasonable limitation, such as nonresponse, inaccurate reporting, or incomplete address lists.
1 mark: Explains how this limitation could affect the accuracy of the inference.
(c)
1 mark: Suggests a valid modification, such as increasing the sample size or improving follow-up with nonrespondents.
1 mark: Justifies how this modification improves reliability (e.g., reduces variability, reduces nonresponse bias).
Total: 4–6 marks depending on accuracy, development, and justification.
