
AP Syllabus focus:
‘Parameters and probabilities related to the sampling distribution for a difference in proportions need to be interpreted with appropriate units and in the context of the specific populations being studied. This involves understanding the meaning and implications of the calculated differences in proportions and the variability of these differences across different samples.’
Understanding how to interpret probabilities and parameters for the sampling distribution of a difference in sample proportions is essential for making context-rich, meaningful inferences about populations.
Interpreting Parameters of the Sampling Distribution
When comparing two population proportions, the sampling distribution of the difference in sample proportions—written as —provides a model for how this statistic behaves across repeated random samples. To interpret this distribution correctly, students must recognize how each parameter links back to the populations being studied and what each probability statement communicates about expected sampling outcomes.
Interpreting the sampling distribution of p^1−p^2\hat{p}_1 - \hat{p}_2p^1−p^2 means thinking of all the differences we could have seen over many random samples, not just the one we actually observed.
Histogram of 1,000 simulated differences in sample proportions across repeated samples. The distribution shows how values of p^1−p^2\hat p_1 - \hat p_2p^1−p^2 cluster around the center with natural sampling variability. The specific red-ball/almond context in the original source exceeds AP requirements, but the statistical structure exactly matches the sampling distribution principles described in these notes. Source.
Mean of the Sampling Distribution
The mean of the sampling distribution describes the average value of over all possible samples of the same sizes.
EQUATION
= True population proportions for Population 1 and Population 2
This parameter must always be interpreted within the context of the specific populations, emphasizing that it reflects the underlying difference in true proportions, not the difference observed in one sample. Recognizing this distinction helps separate population-level reality from sample-level variability.
Interpreting this parameter requires precise language. For example, stating that the mean equals communicates that, on average, repeated samples would yield a difference in sample proportions equal to the actual difference in the population.
Standard Deviation of the Sampling Distribution
The standard deviation of the sampling distribution describes the expected variability of across repeated sampling. It communicates how much fluctuation should naturally occur from sample to sample.
EQUATION
= Sample sizes from Population 1 and Population 2
The interpretation must emphasize both units (proportions) and context. Saying that the standard deviation is, for example, 0.04 is incomplete without clarifying that it represents the expected typical deviation in the difference in sample proportions when repeatedly sampling from the two populations.
Interpreting Probabilities Associated with the Distribution
Probability statements for quantify how likely it is for samples to produce differences of various magnitudes. Proper interpretation requires clearly identifying the populations, the parameter of interest, and the direction and meaning of inequalities.
Contextual Interpretation of Probability Statements
When interpreting a probability such as
“The probability that exceeds 0.10,”
the student must connect this to the likelihood of obtaining a sample difference at least that large when sampling from the two specified populations.
Important elements to highlight include:
the specific populations and the categorical variables involved
the fact that probabilities refer to random samples, not individuals
understanding that probabilities describe outcomes under repeated sampling, not certainty about a single observed difference
Using Proper Units and Comparative Language
Interpretation must reflect that differences in proportions represent comparisons. Students should use phrasing such as:
“Population 1 has a higher proportion of ___ than Population 2,”
or“The sample difference suggests that, in repeated sampling, differences of this magnitude occur with probability ___.”
Avoiding vague statements (e.g., “there is a difference”) is essential. Instead, the interpretation must specify which population has the higher proportion and by how much.
Connecting Parameters and Probabilities to Real-World Meaning
When the normal approximation is valid, the probability for a range of values of p^1−p^2\hat p_1 - \hat p_2p^1−p^2 is represented by the area under a normal curve between the corresponding boundaries.
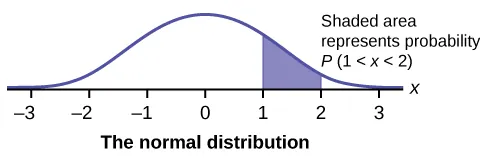
Standard normal curve with the area between one and two standard deviations shaded. This illustrates how probabilities for continuous statistics such as p^1−p^2\hat p_1 - \hat p_2p^1−p^2 or their z-scores correspond to areas under the curve. The exact numerical boundaries (1 and 2) exceed what the syllabus requires but provide a clear visual model for probability interpretation. Source.
Emphasizing Context
Every interpretation should return to the real-world populations being studied. Without context, numerical results lack meaning. Students should be trained to:
name the populations explicitly
name the characteristic being compared
state conclusions in terms of proportions, not counts or percentages of samples
Understanding Variability Across Samples
Because the sampling distribution models how varies, interpretations must acknowledge sampling variability. Proper interpretation might include statements such as:
“Differences in sample proportions will vary from sample to sample,”
or“A difference of this size is typical/atypical under repeated sampling.”
This reinforces the statistical reasoning that conclusions are based not on single samples but on modeled sampling behavior.
Interpreting Extremely Large or Small Differences
Students should recognize that unusually large observed differences (relative to the distribution’s mean and standard deviation) may suggest that:
random sampling variability alone may not explain the result
there may be a meaningful difference between population proportions
However, interpretations should not extend into hypothesis-testing territory; the focus remains on understanding what probabilities and parameters mean, not on conducting formal inference.
Layered Interpretation Checklist
Students can approach interpretation systematically by ensuring that statements include:
Context
Name each population.
Describe the categorical variable.
Parameter clarity
Identify the population difference being estimated.
Statistic clarity
Define the sample difference being described.
Probability interpretation
Express likelihood in terms of repeated sampling.
Units
Use proportion differences, not percentages of individuals.
This layered approach supports consistent, precise interpretation of both parameters and probabilities associated with the sampling distribution for differences in sample proportions.
FAQ
Practical importance depends on the context and the real-world effect size, not the sampling distribution alone.
Consider whether:
• the difference would meaningfully change decisions or outcomes
• stakeholders would view the size of the difference as consequential
• the difference affects behaviour, cost, health, or performance in a tangible way
A difference may be statistically unusual yet too small to matter in practice, or quite large in context even if not rare in the sampling distribution.
This typically indicates the sample result is highly consistent with what would be expected under repeated sampling.
A value near the mean suggests:
• minimal evidence of sample-to-sample extremity
• the observed difference aligns well with the underlying population difference
• the result lies in a region of high probability density
In context, it means your sample does not exhibit unusual behaviour relative to the modelled distribution.
Context links the abstract probability to the real populations being compared.
A contextual interpretation clarifies:
• which groups the proportions refer to
• the characteristic being measured
• the meaning of the inequality (for example, “greater than 0.10”) in real terms
Without context, probability statements become ambiguous and may misrepresent the relationship between the two populations.
Even if the normal approximation holds, skewed population proportions can influence how students interpret variability.
When one proportion is very close to 0 or 1:
• the variability term may differ sharply between groups
• the distribution of possible differences may have a steeper or flatter spread
• the interpretation of tail probabilities may require extra care, even if still modelled with a normal curve
These effects do not violate the subsubtopic’s principles but can influence intuitive expectations.
Probabilities describe long-run behaviour, not certainty about a single observed sample.
Repeated sampling clarifies:
• that the statistic varies naturally
• probability statements refer to the proportion of samples showing certain differences
• interpretation must reflect long-term tendencies rather than deterministic predictions
This framing prevents misinterpretation of probability as a statement about the accuracy of one particular sample outcome.
Practice Questions
Question 1 (1–3 marks)
A researcher compares the proportion of customers who prefer a new product version between two independent shops. She obtains a sample difference in sample proportions of 0.12. Explain, in context, what this observed difference means in terms of the sampling distribution of the difference in sample proportions.
Question 1 (1–3 marks)
• 1 mark: States that the value refers to the difference in sample proportions, not the population proportions.
• 1 mark: Mentions that the result is one possible outcome from the sampling distribution and could vary across repeated samples.
• 1 mark: Provides contextual interpretation (e.g., the sample from Shop 1 had a 12 percentage point higher preference rate than Shop 2 in this sample).
Maximum: 3 marks.
Question 2 (4–6 marks)
A school is investigating whether the proportion of students who bring lunch from home differs between Year 10 and Year 11. A random sample from each year group is taken.
The sampling distribution of the difference in sample proportions (Year 10 minus Year 11) is approximately normal, with mean 0.05 and standard deviation 0.03.
(a) Interpret the mean of the sampling distribution in context.
(b) Interpret the standard deviation of the sampling distribution in context.
(c) A sample difference in sample proportions of 0.11 is observed. Explain how to interpret the likelihood of observing a difference this large or larger in repeated sampling.
Question 2 (4–6 marks)
(a)
• 1 mark: States that the mean represents the expected or average difference in sample proportions across repeated samples.
• 1 mark: Provides correct context (e.g., on average, Year 10 is expected to have a 5 percentage point higher proportion of students bringing lunch from home).
Maximum: 2 marks.
(b)
• 1 mark: States that the standard deviation measures the typical variation in the difference in sample proportions between samples.
• 1 mark: Provides correct context (e.g., differences would typically vary by about 3 percentage points from sample to sample).
Maximum: 2 marks.
(c)
• 1 mark: Recognises that the value 0.11 is compared against the sampling distribution.
• 1 mark: States that the interpretation concerns repeated sampling (e.g., how often a difference of 0.11 or greater would occur by chance).
Maximum: 2 marks.
Total maximum: 6 marks.
