
AP Syllabus focus:
‘Calculate the t-statistic for a sample mean using the formula: t = (x̄ - μ0) / (s/√n), where x̄ is the sample mean, μ0 is the hypothesized population mean, s is the sample standard deviation, and n is the sample size. The t-statistic follows a t-distribution with n - 1 degrees of freedom when the population standard deviation is unknown. For matched pairs, calculate the mean and standard deviation of the differences, then use these in the formula for the t-statistic.’
This section explains how a t-statistic is computed for hypothesis testing about a population mean when the population standard deviation is unknown, highlighting why each component matters.
Calculating the Test Statistic for a Population Mean
The t-statistic is the foundational numerical measure used in a one-sample t-test, quantifying how far the observed sample mean lies from the hypothesized population mean in standardized units. Because the population standard deviation is typically unknown in real research, the sample standard deviation replaces it, introducing additional variability. This adjustment leads to the use of the t-distribution, which is wider and has heavier tails than the normal distribution, especially with small sample sizes.
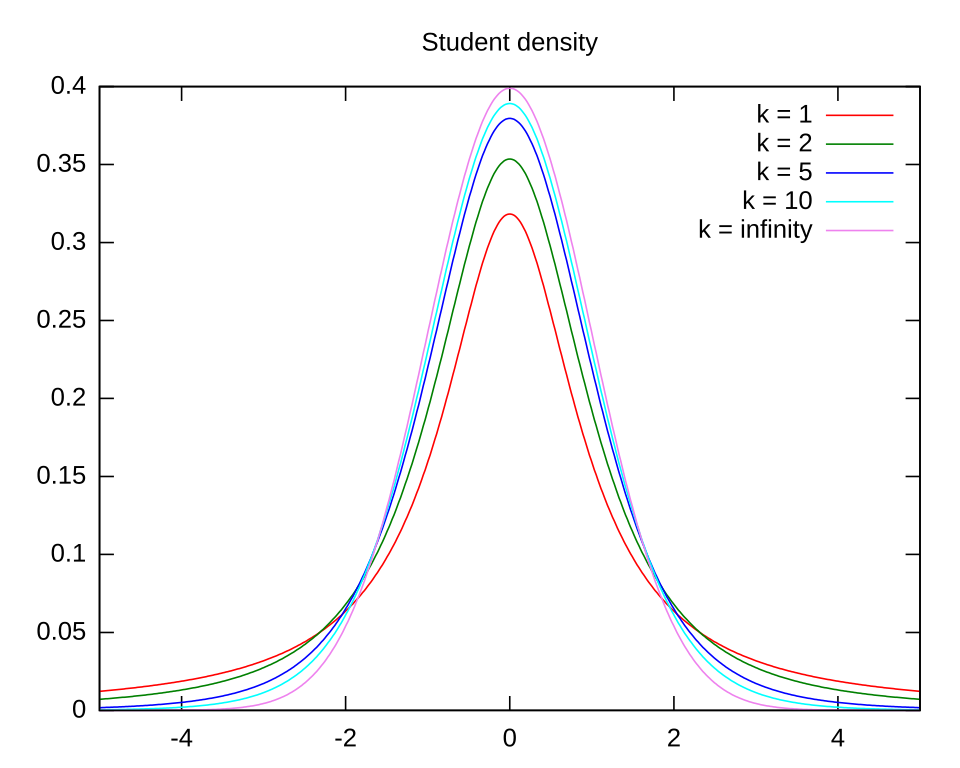
This set of t-distribution curves illustrates how heavier tails arise at low degrees of freedom and how the curves converge toward the normal distribution as sample size increases. Source.
The test statistic allows researchers to evaluate whether the observed data are consistent with the null hypothesis or provide evidence for the alternative hypothesis.
Understanding the Components of the t-Statistic
The test statistic compares the observed sample mean to the hypothesized mean, adjusted for expected sampling variability. To perform this calculation, several core quantities must be used carefully and interpreted correctly.
Sample mean (): The arithmetic average of observed sample values.
The sample mean summarizes the center of the collected data and is the key point of comparison against the hypothesized mean.
Hypothesized population mean (): The value proposed in the null hypothesis for the true population mean.
This hypothesized value establishes the benchmark for assessing whether the sample provides evidence of a difference.
Sample standard deviation (): A measure of variability within the sample, estimating the standard deviation of the population.
Because replaces the unknown population standard deviation in inference procedures, it adds uncertainty reflected by the t-distribution.
Sample size (): The number of observations in the sample used to estimate the population mean.
Sample size influences the precision of the estimate and determines the degrees of freedom, which affect the shape of the t-distribution used to determine probabilities associated with the test statistic.
A clear understanding of these components ensures that the calculated test statistic accurately reflects the strength of evidence in the data.
The Formula for the Test Statistic
The AP Statistics syllabus requires mastery of the formula used to compute the t-statistic in a one-sample mean test. This calculation standardizes the difference between the sample mean and the hypothesized mean by dividing by the standard error, which represents the expected variation of sample means.
EQUATION
= Sample mean
= Hypothesized population mean
= Sample standard deviation
= Sample size
This formula yields a value measured in standard error units, indicating how unusual the sample result would be if the null hypothesis were true.
After calculating the statistic, it is interpreted using the t-distribution with degrees of freedom, which adjusts for the estimation of variability using sample data rather than known population parameters.
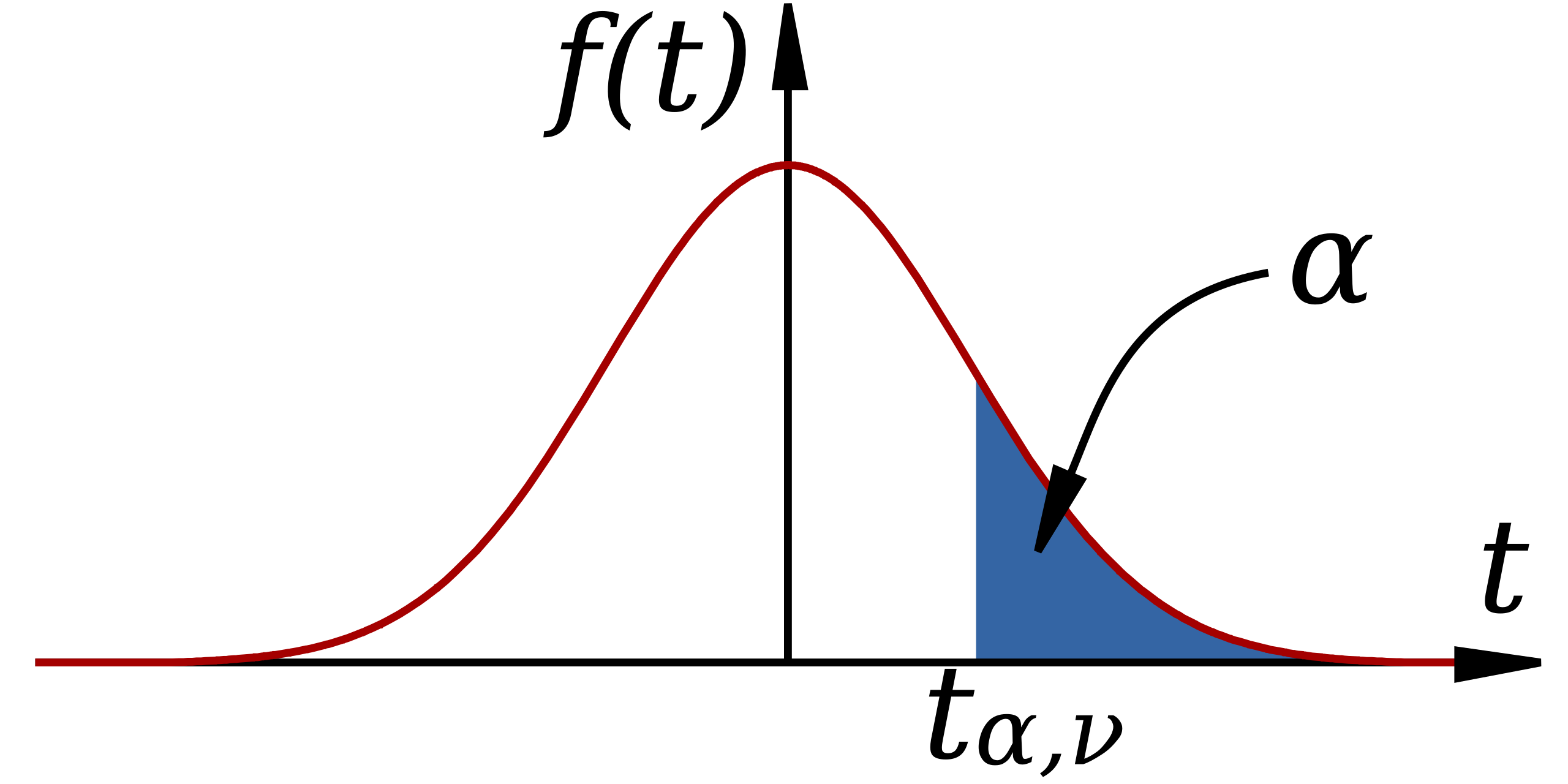
This diagram highlights a critical value on a t-distribution curve, showing how calculated t-statistics are interpreted relative to degrees of freedom and associated tail areas. Source.
Why the t-Distribution Is Required
When the population standard deviation is unknown—almost always in practical settings—replacing it with the sample standard deviation introduces additional variability. The t-distribution compensates for this by stretching its tails, increasing the probability of more extreme values. As sample size grows, the sample standard deviation becomes a more stable estimate, causing the t-distribution to closely approximate the normal distribution. This behavior ensures that the test statistic is assessed using an appropriate reference distribution that accounts for uncertainty inherent in the data.
Calculating the Test Statistic for Matched Pairs
The syllabus also specifies that matched-pairs designs require computing differences within each pair before applying the same one-sample t-test procedure. This reframing converts the paired data into a single quantitative variable: the set of differences.
Difference variable (): A new variable formed by subtracting paired observations in a consistent order to measure within-pair change.
Once these differences are computed, the same components used in the one-sample t-test apply, but now to the mean and standard deviation of the differences. This ensures that the analysis targets the change within subjects or matched units, rather than comparing paired observations independently.
In matched-pairs settings, the test statistic evaluates whether the mean difference in the population is equal to the hypothesized value specified in the null hypothesis. The procedure maintains the same form as the one-sample mean test but uses the difference statistics instead of original measurements.
Interpreting the Role of Degrees of Freedom
The degrees of freedom, calculated as , reflect the number of independent pieces of information available to estimate the population standard deviation. This affects the exact shape of the t-distribution used to determine probabilities associated with the test statistic. Smaller samples yield fewer degrees of freedom, widening the distribution and requiring stronger evidence (a larger absolute test statistic) to question the null hypothesis. As sample size increases, the distribution narrows, improving the precision of the test.
Structural Overview of the Calculation Process
To ensure clear understanding and strong procedural habits, the essential components of calculating the test statistic include:
Identifying the sample mean and hypothesized mean for comparison.
Determining the sample standard deviation to estimate population variability.
Computing the standard error using .
Standardizing the difference between and using the t-statistic formula.
Referring to the correct t-distribution based on degrees of freedom.
Applying the same structure to matched-pairs data using differences.
Each step contributes to producing a valid and interpretable test statistic that aligns with the AP Statistics inference framework.
FAQ
The sign shows the direction of the difference between the sample mean and the hypothesised population mean.
A positive t-statistic indicates that the sample mean is greater than the hypothesised mean, while a negative value shows it is smaller.
The magnitude, not the sign, determines how extreme the result is when compared with the t-distribution.
The sample standard deviation is an estimate rather than a fixed population value, so it varies from sample to sample.
This added variability widens the reference distribution used to judge the t-statistic, which is why the t-distribution has heavier tails and depends on degrees of freedom.
Outliers affect both the sample mean and standard deviation, meaning the t-statistic can shift dramatically.
If outliers inflate the standard deviation, the test statistic becomes smaller in magnitude, reducing evidence against the null hypothesis.
If outliers shift the mean, the statistic may become artificially large.
Routine data inspection is essential before calculating the test statistic.
Using the sample mean to estimate variation removes one piece of independent information from the dataset.
Degrees of freedom represent the number of values free to vary when calculating the sample standard deviation.
This adjustment ensures the shape of the t-distribution correctly reflects the uncertainty present in estimating population variability.
Inconsistent subtraction reverses the sign of some differences, distorting the average difference and resulting test statistic.
To ensure the statistic reflects a meaningful direction of change, every pair must be calculated in the same order, such as new minus old or treatment minus control.
A consistent rule allows the computed t-statistic to correspond properly to the hypotheses being tested.
Practice Questions
Question 1 (1–3 marks)
A nutritionist claims that the mean sodium content of a brand of soup is 600 mg. A random sample of 12 cans shows a sample mean of 615 mg with a sample standard deviation of 40 mg.
Calculate the test statistic for testing the nutritionist’s claim using a one-sample t-test.
Question 1 (1–3 marks)
• Correct substitution into the t-statistic formula: (615 − 600) divided by (40 divided by square root of 12). (1 mark)
• Correct calculation of the standard error: 40 divided by square root of 12. (1 mark)
• Correct numerical value of the t-statistic (approximately 1.30). Allow minor rounding differences. (1 mark)
Question 2 (4–6 marks)
A sleep researcher tests whether a new relaxation audio track changes the mean number of minutes it takes adults to fall asleep. A random sample of 16 adults listens to the recording for one week. The average change in time to fall asleep (new minus old) is -6.2 minutes, and the sample standard deviation of the changes is 15.5 minutes.
(a) State the null hypothesis and the alternative hypothesis for this test.
(b) Calculate the test statistic for assessing whether the audio track has any effect on mean time to fall asleep.
(c) Explain, without performing any further calculations, how this test statistic would be used to decide whether to reject the null hypothesis.
Question 2 (4–6 marks)
(a) Hypotheses (2 marks total)
• Null hypothesis correctly stated as: the mean change is 0, or the audio track has no effect. (1 mark)
• Alternative hypothesis correctly stated as: the mean change is not 0 (two-sided test). (1 mark)
(b) Test statistic (2–3 marks total)
• Correct substitution into the t-statistic formula using -6.2 minus 0, and standard error based on 15.5 divided by square root of 16. (1 mark)
• Correct calculation of the standard error: 15.5 divided by 4. (1 mark)
• Correct numerical value of the t-statistic (approximately -1.60). Allow minor rounding differences. (1 mark)
(c) Interpretation (1 mark)
• Clear explanation that the test statistic would be compared with the critical values or used to obtain a p-value from the t-distribution with 15 degrees of freedom, and that this comparison determines whether the null hypothesis should be rejected. (1 mark)
