
OCR Specification focus:
‘Explain how gene sequencing enables genome-wide comparisons, prediction of polypeptide amino-acid sequences, and developments in synthetic biology and bioinformatics.’
Modern gene sequencing technologies allow scientists to analyse entire genomes rapidly, enabling comparison across species, prediction of protein structures, and the design of novel biological systems through synthetic biology.
Genome-Wide Comparisons
Understanding Genome Sequencing
Gene sequencing involves determining the exact order of nucleotides (A, T, C, G) in a DNA molecule. Once entire genomes are sequenced, they can be compared to identify genetic similarities and differences between organisms.
Genome: The complete set of genetic material (DNA) present in an organism or cell.
Comparing genomes has become increasingly accurate and efficient due to high-throughput sequencing techniques such as next-generation sequencing (NGS), which can process millions of fragments simultaneously.
Applications of Genome Comparisons
Genome comparison underpins much of modern biology and has numerous applications:
Evolutionary relationships: Comparing conserved genes reveals evolutionary links between species and helps construct phylogenetic trees.
Identification of genes and functions: Comparing genes with known sequences in databases allows prediction of unknown gene functions.
Medical genetics: Identifying mutations associated with genetic disorders, cancer, or disease susceptibility.
Epidemiology: Tracing the origins and spread of pathogens by comparing their genome sequences.
Conservation biology: Assessing genetic diversity within and between populations to guide conservation efforts.
Comparative Genomics and Bioinformatics
Comparative genomics relies heavily on bioinformatics, which uses computational tools to store, analyse, and interpret vast quantities of sequence data.
Bioinformatics: The application of computer technology to the management and analysis of biological data, especially genetic sequences.
Key bioinformatics methods include:
Sequence alignment algorithms (e.g. BLAST) to identify similarities and homologies between sequences.
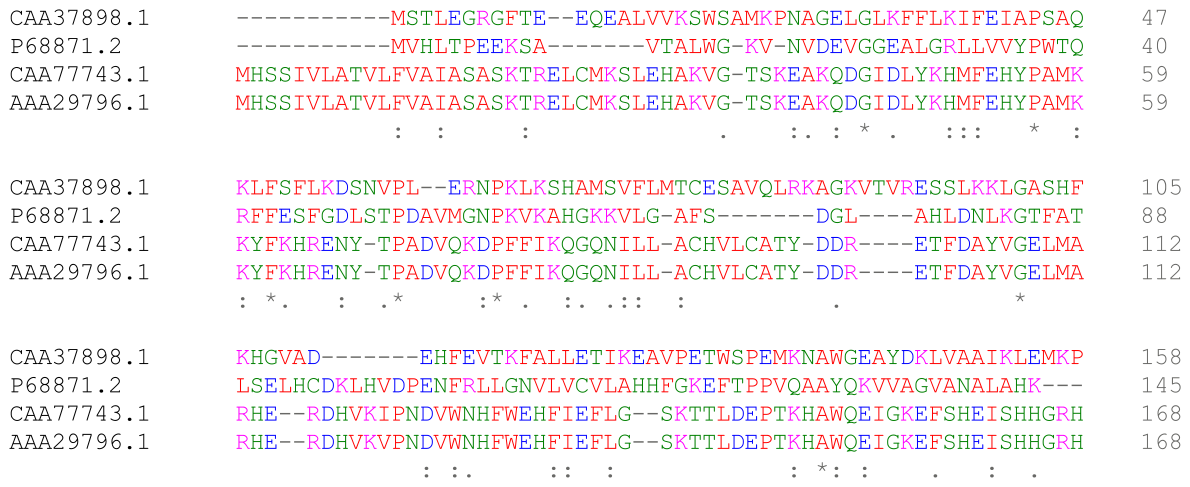
Multiple sequence alignment of homologous proteins highlights conserved positions and insertion/deletion sites. Such alignments underpin comparative genomics and the inference of evolutionary relationships. The clear consensus markers help students recognise conserved motifs used for function prediction. Source.
Annotation to locate genes, regulatory regions, and repetitive sequences.
Database searches (e.g. GenBank, EMBL, Ensembl) to compare new sequences with existing ones.
Through such analyses, scientists can trace gene conservation, identify gene duplication events, and study genomic evolution.
Prediction of Polypeptide Amino Acid Sequences
From Gene to Polypeptide
Because genes code for proteins, sequencing DNA allows prediction of the amino acid sequence of a polypeptide.
Polypeptide: A chain of amino acids joined by peptide bonds, forming the primary structure of a protein.
The process involves several steps:
Identify coding regions (exons): Introns and non-coding DNA must be excluded from the analysis.
Transcribe DNA to mRNA: Predict the mRNA sequence using base-pairing rules (A→U, T→A, C→G, G→C).
Translate mRNA to amino acids: Apply the genetic code, which defines how triplets of bases (codons) correspond to specific amino acids.
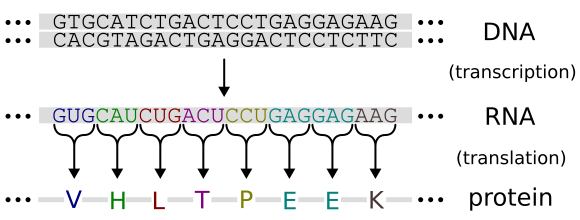
Diagram of the genetic code linking mRNA codons to amino acids, illustrating how DNA sequence determines a polypeptide’s primary structure. This figure reinforces the transcription-translation flow used for amino-acid sequence prediction. Minor contextual detail relating to haemoglobin is included but not required by the syllabus. Source.
The resulting amino acid sequence determines the protein’s primary structure, which in turn affects its secondary, tertiary, and quaternary structures.
Importance of Polypeptide Prediction
Predicting amino acid sequences is vital for:
Understanding protein function and how mutations alter function.
Identifying active sites or binding domains in enzymes.
Designing drugs that interact with specific proteins.
Developing diagnostic tests for defective proteins caused by genetic mutations.
Mutation: A change in the DNA base sequence that may alter the amino acid sequence of a protein, potentially affecting its function.
Furthermore, bioinformatics databases allow researchers to model protein folding and predict three-dimensional structures, leading to insights into protein activity and stability.
Developments in Synthetic Biology
Overview of Synthetic Biology
Synthetic biology is an interdisciplinary field that applies principles of engineering to design and construct new biological parts, systems, or organisms.
Synthetic Biology: The design and construction of new biological entities or systems, or the redesign of existing biological systems for useful purposes...
By using gene sequencing data, scientists can identify useful genes from various organisms and combine them to create new genetic constructs.
Applications of Synthetic Biology
Synthetic biology enables:
Gene modification and assembly: Designing artificial gene circuits to control gene expression.
Production of pharmaceuticals: Creating microorganisms that synthesise complex drugs, such as insulin or antibiotics.
Biofuel development: Engineering bacteria or algae to produce sustainable energy sources.
Bioremediation: Designing microorganisms capable of breaking down pollutants or absorbing heavy metals.
Agricultural improvements: Producing crops with enhanced nutritional value, disease resistance, or environmental tolerance.
Relationship with Bioinformatics
Bioinformatics supports synthetic biology by providing:
Design software to predict the outcome of new genetic constructs.
Databases of gene sequences and biological parts (e.g. the Registry of Standard Biological Parts).
Modelling tools to simulate genetic networks and metabolic pathways before laboratory synthesis.
These developments rely on vast amounts of sequencing data, allowing genes to be synthesised artificially without needing natural templates.
Integrating Genome Comparisons, Protein Prediction and Synthetic Biology
Modern biology increasingly integrates these three aspects:
Genome sequencing supplies the raw data.
Bioinformatics analyses and interprets the data to predict protein structure and function.
Synthetic biology applies this knowledge to construct new biological systems.
For example:
Comparative genomics might identify a gene conferring drought resistance in one plant species.
Bioinformatic tools could predict the protein’s structure and mechanism.
Synthetic biologists could then insert the gene into another crop to enhance its resilience.
Such integration illustrates the power of modern molecular biology to understand, predict, and engineer life at the genetic level — a core goal of the OCR A-Level Biology specification for this topic.
Practice Questions
Question 1 (2 marks)
Explain how comparing gene sequences from different organisms can provide evidence for evolutionary relationships.
Mark Scheme:
1 mark: States that similarities in DNA or gene sequences indicate shared ancestry.
1 mark: Explains that greater sequence similarity suggests a closer evolutionary relationship (or less time since divergence).
Question 2 (5 marks)
Describe how advances in gene sequencing and bioinformatics have contributed to developments in synthetic biology.
Mark Scheme:
1 mark: Mentions that modern sequencing techniques (e.g. next-generation sequencing) provide rapid, large-scale DNA sequence data.
1 mark: States that bioinformatics is used to analyse and compare these DNA sequences to identify useful genes or biological parts.
1 mark: Explains that identified genes can be synthesised artificially or combined to create new genetic constructs.
1 mark: Describes how this allows design and construction of gene circuits or modified organisms for specific purposes (e.g. drug production, biofuels, bioremediation).
1 mark: Links the use of sequencing and bioinformatics directly to the development and testing of synth
FAQ
By comparing the genomes of individuals or species with and without a trait, scientists can identify shared genetic regions or mutations linked to that characteristic.
Researchers look for conserved sequences or single nucleotide polymorphisms (SNPs) that consistently appear in those showing the trait.
This approach is used in Genome-Wide Association Studies (GWAS) to find genes associated with human diseases or useful plant and animal traits.
Sequence alignment involves comparing DNA, RNA, or protein sequences to identify regions of similarity that may indicate shared function or ancestry.
Genome annotation, by contrast, identifies and labels features within a genome such as genes, regulatory elements, or repetitive DNA.
In practice, alignment provides the comparative data, while annotation interprets that data to predict gene function and location.
Bioinformatics tools use known protein databases to compare new sequences against existing structures.
Prediction methods include:
Homology modelling: assumes similar sequences fold into similar structures.
Threading: fits sequences into known structural frameworks.
Ab initio modelling: predicts folding patterns from physical and chemical properties of amino acids.
These models help infer protein function, binding sites, and stability without direct experimental data.
A genetic circuit is a set of genes and regulatory elements arranged to perform a specific logical function, similar to an electronic circuit.
Designers use standardised genetic parts (e.g. promoters, repressors, terminators) stored in databases.
Bioinformatic modelling predicts how these parts interact, allowing researchers to simulate system behaviour before constructing it in microorganisms like E. coli.
Common examples include toggle switches, oscillators, and biosensors.
Different organisms prefer specific codons for the same amino acid, a phenomenon known as codon bias.
If a synthetic gene uses codons rarely used by the host organism, protein expression may be inefficient.
Scientists therefore optimise codon usage to match the host’s tRNA availability, improving translation speed and protein yield.
Codon optimisation is a key bioinformatic step in synthetic biology when transferring genes between species.
