
AP Syllabus focus: 'Descriptions of quantitative distributions include shape, center, variability or spread, and unusual features such as outliers, gaps, clusters, or multiple peaks.'
When you describe a quantitative distribution, you translate a graph into statistical language. A complete description explains the overall pattern, where typical values lie, how much the values vary, and whether anything stands out.
Describing a Quantitative Distribution
In AP Statistics, a distribution is usually described from a histogram, dotplot, or stemplot. The goal is not to list every data value. Instead, identify the most important visual features and explain them in context of the variable being measured.
Distribution: The overall pattern of values for a quantitative variable, including where values are concentrated and how they vary.
A useful description tells a reader what the data look like without showing the graph. For one-variable quantitative data, focus on four ideas: shape, center, spread, and unusual features.
Shape
Shape refers to the overall form of the distribution. Ask where most observations are, how the tails behave, and how many prominent peaks appear.
A distribution may be roughly symmetric, meaning the left and right sides look similar.
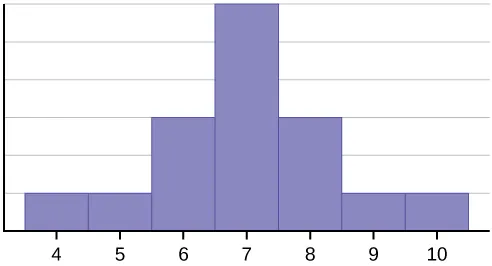
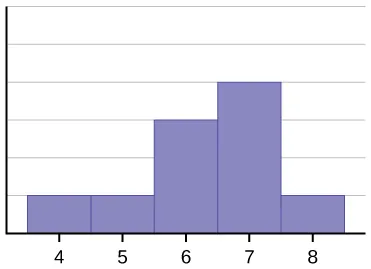
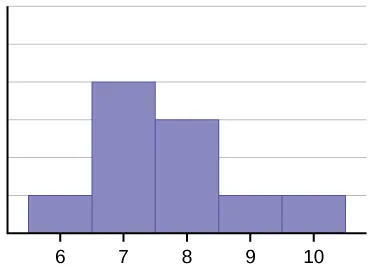
Three contrasting histograms illustrate a symmetric distribution and two skewed distributions (left-skewed and right-skewed). The side with the longer tail identifies the direction of skew, which is the core visual cue students should translate into words when describing shape. Seeing the three shapes side-by-side makes it easier to connect “overall form” and “tail behavior” to precise statistical language. Source
It may be skewed right, with a longer tail on the high-value side, or skewed left, with a longer tail on the low-value side. Shape also includes modality: some distributions have one clear peak, while others have two or more distinct peaks.
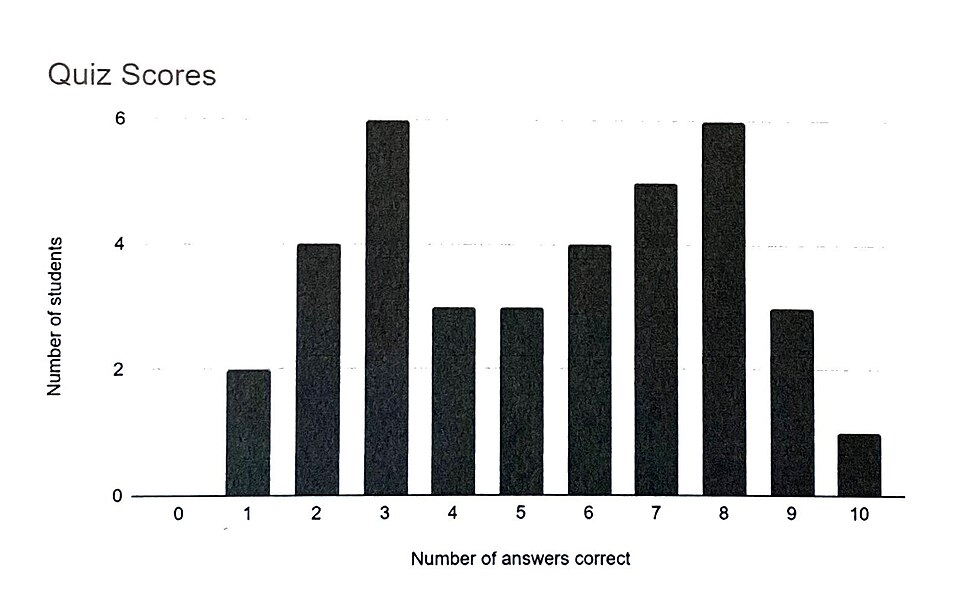
A bimodal distribution is shown with two distinct peaks separated by a lower-density “valley.” This is a canonical example of why a single measure of center can be misleading: the mean or median may fall near the valley even though relatively few observations occur there. The figure supports careful description of shape by explicitly highlighting multiple peaks as part of the overall pattern. Source
In some cases, bars or dots are spread fairly evenly across values, giving an approximately uniform appearance.
When describing shape, use cautious language such as approximately, appears, or roughly. Real data are rarely perfectly symmetric or perfectly uniform.
Center
Center: A value that describes the middle or typical location of a distribution.
Center is the location of a typical observation. On a graph, it is often estimated rather than read exactly. For example, you might say that the distribution is centered around 52 minutes or that a typical score is in the mid-70s.
The center should match the shape of the data. If the distribution is fairly symmetric, the mean and median are often close, so either idea of center may represent the data well. If the distribution is strongly skewed, the median is often a better description of a typical value because extreme values can pull the mean toward a tail. Even when you do not calculate a statistic, you should still identify the general location of the center.
Spread
Spread: The amount of variability in a distribution, showing how far observations extend or how tightly they cluster.
Spread describes how much the observations vary. A distribution with little spread has values packed closely together. A distribution with large spread has values scattered over a wider interval. Two data sets can have the same center but very different spread, so both features matter.
On graphs, spread is usually described with words and approximate intervals. You might note that values run from about 10 to about 90, or that most observations fall between 30 and 45. Spread helps answer whether the data are consistent or highly variable. When writing in context, describe spread using the variable's units, since a spread of 5 could mean very different things for test scores, ages, or reaction times.
Unusual Features
After describing the general pattern, look for values or regions that do not fit the rest of the distribution. These are unusual features.
Outlier: A data value that lies far from the overall pattern of the rest of the distribution.
An outlier may suggest an error, but it may also be a real and important observation. Do not automatically remove it or assume it is wrong; simply note that it is separated from the main body of data.
Other unusual features include gaps, clusters, and multiple peaks. A gap is an interval with no observations. A cluster is a region where many observations are grouped closely together. Multiple peaks can indicate that the data may come from different subgroups or that more than one common value exists. These features matter because they can hide behind simple summaries. For example, a single center may not describe a bimodal distribution very well, and a wide spread may actually reflect two separate clusters rather than one broad pattern.
Writing a Strong Description
A complete AP Statistics description should be specific, concise, and connected to the context.
Identify the variable and its units.
Describe the shape using terms like symmetric, skewed, unimodal, or bimodal.
Give an approximate center.
Comment on the spread using an interval or a general statement about variability.
Mention any unusual features, such as outliers, gaps, clusters, or multiple peaks.
Use contextual language, such as "student study times" or "daily temperatures," not just "the data."
Good descriptions combine several features in one sentence or short paragraph. Instead of saying only that a graph is skewed, explain where it is centered, how wide it is, and what stands out. That fuller description is what makes statistical communication useful.
Practice Questions
A histogram of household sizes in a neighborhood is unimodal with a long right tail. Most households have 2 to 4 people, and one household has 9 people. Describe two features of this distribution.
1 mark for identifying the shape as right-skewed or describing a long right tail
1 mark for identifying either a center around 2 to 4 people or the unusually large value of 9 people as an outlier/unusual feature
A histogram shows the distribution of waiting times, in minutes, for patients at a clinic. Most waiting times are between 5 and 25 minutes, with one main peak near 15 minutes. The distribution extends to about 70 minutes, has a gap from about 40 to 55 minutes, and includes two very large waiting times near 65 and 70 minutes.
Write a complete description of the distribution in context.
1 mark for identifying the context as clinic waiting times
1 mark for describing the shape as right-skewed or stating there is a long right tail
1 mark for giving a reasonable center, such as around 15 minutes
1 mark for describing spread, such as from about 5 to 70 minutes or stating that the distribution has a wide spread
1 mark for identifying unusual features, such as the gap from 40 to 55 minutes and/or the high outliers near 65 and 70 minutes
FAQ
Graphs are visual summaries, so exact features are often hard to read precisely. A tail may look slightly longer on one side just because of random variation.
Using cautious language shows statistical honesty. It tells the reader that the description is based on the visible pattern, not on a claim of perfect shape.
Yes. In some settings, the unusual value is exactly what matters most.
In quality control, an outlier may signal a defect.
In medicine, it may identify a patient needing urgent attention.
In business, it may reveal a rare but costly event.
That is why outliers should be investigated, not ignored automatically.
The appearance of a distribution can change if the graph is constructed differently.
Wider histogram bins can hide gaps or combine two peaks into one.
Narrower bins can make random noise look like extra clusters.
Rounded data values can create artificial piles at certain numbers.
This is why statisticians try to match the display to the data and avoid overinterpreting small visual changes.
Use careful wording and describe what you actually see. A single center may not be very informative for a distribution with two clusters or two peaks.
You can say that the data have no single obvious center, then describe the locations of the separate groups. That is often more accurate than forcing one middle value onto a clearly split distribution.
With a very small sample, the graph may look irregular even if the underlying process is not unusual. A few observations can create apparent skewness or fake gaps.
In that case:
use more cautious language
mention exact unusual values if they matter
avoid strong claims about symmetry or modality
Small samples can still be described, but the description should be more tentative.
